
Idea: The advent of deep reinforcement learning - with strong results in Atari, Go, and other Games - may enable us to reimagine how we build systems. Instead of carefully constructing policies, systems programmers can focus on creating small, but correct, submodules and training agents to combine these submodules into higher program behavior. These systems outperform the classical programs based on fixed policies by continuously adapting to access patterns in real time.
To prove out this idea, we trained a deep q-learning model to construct skip list internal structures to minimize key lookup time. The code is available here: RLSL: Reinforcement Learning for Skip Lists. Our agent performs well in the presence of uniform as well as non-uniform access.
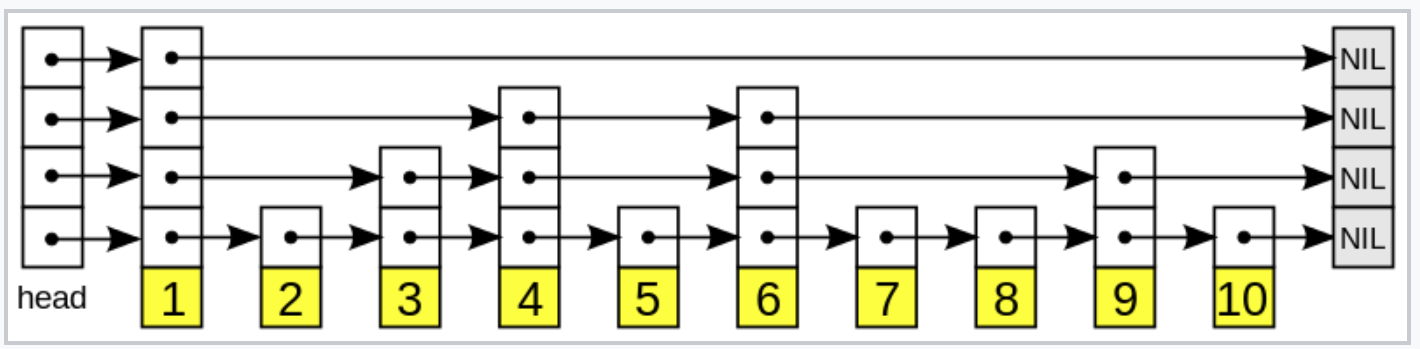
Skip lists
First detailed by William Pugh in 1989, a skip list is a probabilistic data structure alternative to balanced trees that provides for fast lookups for key ranges. It is a collection of sorted linked lists: a base list and a hierarchy of descending linked lists. Pugh showed that given a uniform key access pattern, the expected lookup time for a element is logarithmic in the length of the skip list when node height is randomly chosen. The probabilistic nature of the skip list creates a tolerance to a broad collection of optimal solutions for internal structure making it a natural data structure for learning problems. The mechanism of key storage and lookup is simple - it can be implemented correctly in a few lines of code. We devised a clean interface between policy and implementation by decoupling the policy from the mechanism of setting heights.
The Agent
Our agent trains on state frames that include current skip list internal structure, access patterns heatmaps, access distributions, and key lookup distribution. Our model uses 2d convolutions to process the internal structure and access pattern heatmaps, 1d convolutions to process the access and key lookup distributions, and fully connected layers to resolve the final output. The reward signal is the reciprocal of the log of the average length of lookup path. On each turn, the agent is given the ability to choose one of six actions: set height to 0, 1, 2, or 3, move left or move right. We trained a deep q-learning network with experience replay based on the implementation from the pytorch tutorial. In order for our network to train, we introduced batch normalization and a learning rate schedule. We used the same network and training system on both uniform and peak distributions.

Results
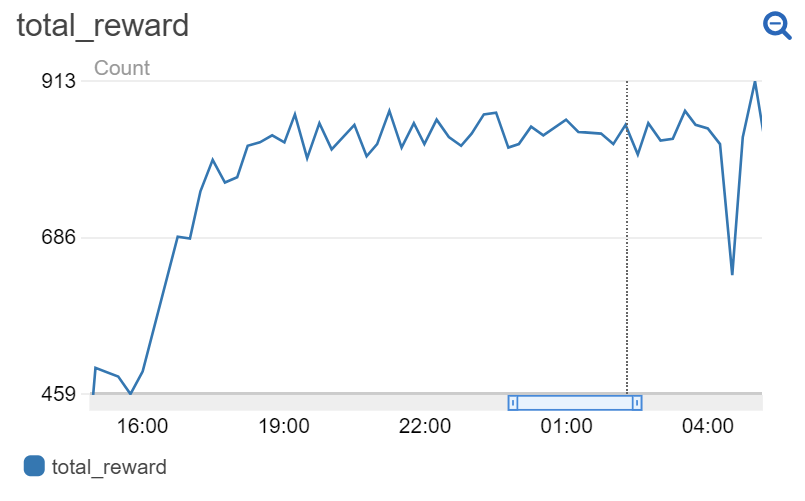
When play begins, the agent is given a skip list with an empty internal structure - every lookup must begin at the beginning of the list and traverse sequentially to find the corresponding entry. The agent successfully learns to construct skip list structure, setting the internal heights of the elements, to rapidly drive up reward i.e. minimize lookup path length. We trained the agent for ~100 games, each game running for 2000 turns. Performance is generally poor for the first 30 (60,000 turns) games before play improves. While the agent does learn to play well in the presence of peaked rather than uniform data access, further training and tuning would improve peaked play.
Future
In this piece, we showed the ability of current day reinforcement learning algorithms to perform well in historical systems tasks such as data structure construction. This current implementation is slow - it is nowhere near the performance needed for production workloads. However, the principles embodied here could be applied more broadly. Databases could be constructed where the internal structure automatically adapts to user access pattern, enabling performant keyless databases. Garbage collection could be based on program performance and automatically tuned. Systems may self assemble e.g. automatically determine the number of caching layers and the type of backing storage. Overall, the nature of the work in systems programming will change - to remain on the cutting edge, the systems programmer will need to incorporate agents to learn policies from experience rather than construct solely closed solutions.
{kind=link}