
Browsing Craigslist one day, it occurred to me that all the parts for a small data center were available, within driving distance of my home, at significantly discounted prices. Racks, servers, rails, power supplies, switches, and routers. Maybe the migration to cloud really is in full swing with every business dumping their on-prem gear. Combined with the proliferation of inexpensive and open source software components, such as Ubuntu & Kubernetes, building an at home data center, which is cloud provider feature comparable, isn't as hard or costly as it once was.
We are a house of all software engineers and I focus on infrastructure, so I was convinced this would be a fun project. At roughly $50 per month in power, it wouldn't be too much of an ongoing cost and it would give us a place to deploy software without paying cloud fees.






Acquiring the parts
We were able to locate the major components on Craigslist i.e. the physical racks and the servers. I have a panel van, so transport was not an issue. (We actually got three racks for the price of one, so I stored the other two for later). For the servers, we wanted a decent amount of processors and ram, but cared less about disk: it's not really durable anyway if it isn't replicated and backed up. The other issue was making sure that the servers came with a rail kit. These kits can be 50% of the cost of a used server! I cheated for power distribution and networking, i.e. bought them Newegg / Amazon, because fulfilling them on Craigslist was too hard. For power distribution, bad gear is a safety issue, and for networking, I had specific demands that are detailed later.
The BoM
| Component | Cost | Count | Supplier |
|---|---|---|---|
| Rack | $20 | 1 | Craigslist |
| Server + rails | $200 | 4 | Craigslist |
| Edge Router 4 + rack kit | $249 | 1 | Ubiquiti |
| Netgear switch JGS524 | $119 | 1 | Newegg |
| Power supply RKPW081915 | $47 | 2 | Newegg |
| Power cable, ethernet, screws | ~$100 | - | Newegg + Amazon |
I capped my target spend at $1,000 but went over with a total of $1,382.
The servers are each Dell Poweredge R620 with 12 physical cores / 24 hyper threads, 64GB of ram, 4 1Gb/s nics, dual power supplies, 2 ~100GB ssds, and 8 total hot swap drive bays. So the total cluster has 256GB of ram, 96 cores, and ~800GB of SSD.
Physical assembly
The racks were pretty easy to build: we used an impact driver to speed the assembly. Dell's rapid rails are a little tricky to get on at first, but are awesome once you watch the training video. We located the video by scanning the QR code on the servers: nice touch! The only painful part was the old rack took screws directly, rather than cage nuts, so we had a trip to home depot to size screws. The wiring (power, networking) is all push to connect so there were no assembly problems. For power, since we have an old house, we divided the load across two different circuit breakers.
Static IPs: AT&T
A data center without networking isn't very useful right? You could use dynamic DNS, but caching will cause problems and many services require a dedicated IP. Luckily, we have AT&T fiber service in our neighborhood and they will assign you a static IP block for a small fee: $15 per month for a block of eight with five usable addresses. You can purchase larger blocks as well for a higher monthly fee. You have to call to get this service and you will spend time in the phone tree: this is an unusual request. Furthermore, once it is "set up" it may not work: you need to call AT&T back and fight your way through the phone tree to get someone to correctly set up the routing. Overall, expect to spend at least two weekends on this.
Bare metal Kubernetes
To begin the setup of the software stack, we installed Ubuntu 18.04 (LTS) on all of the nodes. Of the various distributions, I know Ubuntu best and its large community makes finding Q&A support on the internet relatively easy. We then installed docker and the utilities for installing Kubernetes: kubeadm, kubelet, and kubectl.
We next used kubeadm to provision a Kubernetes cluster with a single API server and single node etcd cluster (kubeadm defaults). We could use multiple nodes for these core services, but we only have one site, so since our failures are correlated, replication efficacy is reduced. This is also a side project for fun, so I wanted to get some results. We used Calico for our container networking
It is a bit frustrating to configure and maintain a Kubernetes cluster with kubeadm because making a mistake during configuration often requires tearing down the cluster and starting again in order to remediate the issue. We had to do this twice. Once for changing the host name of our nodes, and again to add an external IP address for our master (i.e. changing SAN on the certs).
Load balancing with MetalLB
Kubernetes is fundamentally a cloud technology, so it has limited support for load balancing and storage in an on-prem environment. We are fine using only local drives, but we felt that we needed some sort of load balancing to make the cluster useful.
Therefore, once the cluster was provisioned, we installed MetalLB and Istio for building our load balancing system. MetalLB leverages BGP to announce the different entry points into our cluster to the Ubiquiti Edgerouter. The Edgerouter then does equal cost multi-path routing (ECMP) to provide L4 load balancing of the TCP flows. Istio ingress gateways receive these packets and then do L7 load balancing for HTTP. It is hard to find an inexpensive router with BGP and ECMP support. We originally tried to use one node with PFSense as the router, but the support for these protocols was too limited.
Network Diagram
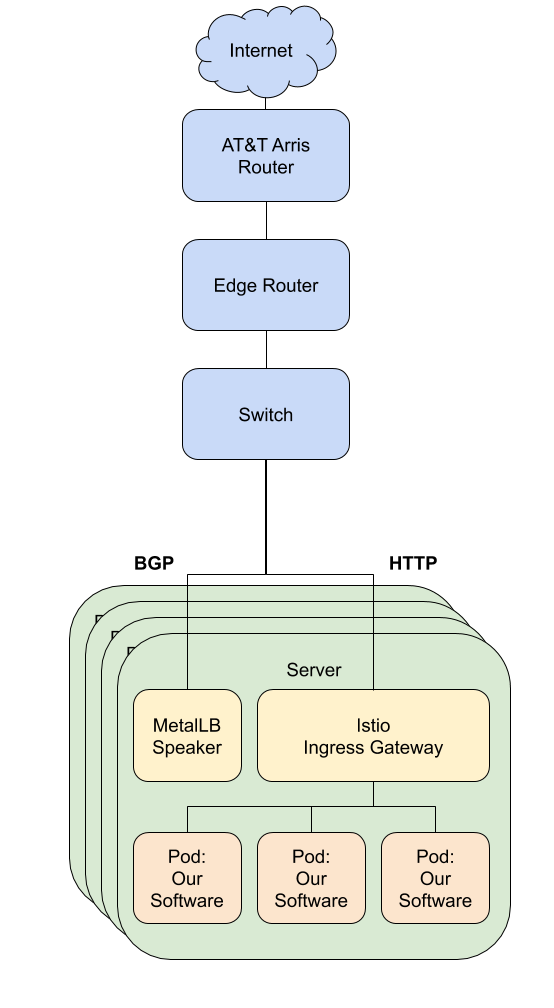
Operational challenges
The California power outages this year have been very frustrating. Even short outages take out the cluster, causing issues. For example, I originally installed Canonical Landscape to help administer the servers - it has a great feature where it scans and updates all packages in apt for security holes - but a power outage broke the installation and a reinstall failed as well. In general, cluster restarts surface many issues e.g. Kubernetes does not tolerate having swap enabled and will fail to boot without making sure that swap is disabled. This is fine, but the default command (swapoff) does not persist between restarts.
We ended up running an internal DNS server (bind) to allow for using hostnames and split DNS. We use Route53 to do external health checks of the cluster. If the mechanism to alert you that the cluster is down is part of the cluster, then you won't get an alert when it is down.
We still have more services that we wish to setup to ease operations:
- LDAP for user accounts
- Vault for encrypting Kubernetes secret storage
- An offsite backup mechanism
- Power backup for the networking and at least the Kubernetes master node for a short outage.
- Cert manager to provision certificates via letsencrypt.
- Security scanning and package update mechanism.
CI / CD
Code storage needs to be geographically replicated, so we use github to store all source code. We love Github actions and the new container registry because they simplify running builds on a commit. We use Azure's plugins to push manifests from github to our cluster on build, and cluster pulls containers from Github's registry.
Software & services
- Kubernetes
- Kubeadm
- Docker
- Bind
- Github (repos, actions, container registry)
- MetalLB
- Istio
- Calico
- cert-manager
- Route53
- Canonical Landscape
{kind=link}